Parallelized Cloud Computing with Dask for Geoscientists#
Tutorial by Ellianna Abrahams
The following notebook includes materials from notebooks written by Hamed Alemohammad, Ryan Abernathy, Planetary Computer, stackstac, and Dask.
For those that would like to follow along for the introductory section, please install graphviz.
conda install python-graphviz
An Introduction to Dask for Parallel Computing#
Dask is a Python library designed to facilitate parallel computing and distributed data processing. It is particularly useful for handling computations that exceed the available memory of a single machine and for parallelizing tasks across multiple cores or even distributed clusters of machines. The primary goal of Dask is to provide a user-friendly and Pythonic interface for developers to scale their data analysis and processing workflows.
Dask consists of two main components:
“Big Data” Collections: Dask provides collections that extend common Python data structures, such as arrays, dataframes, and lists, to handle larger-than-memory or distributed datasets. These collections are designed to mimic the interfaces of popular libraries like NumPy and Pandas, making it easier for developers to transition from single-machine to distributed computing environments.
Dynamic Task Scheduling: Dask provides scheduling that manages the distribution and execution of tasks across the available computing resources. It ensures that computations are carried out efficiently in a parallelized manner.
 High level collections are used to generate task graphs which can be executed by schedulers on a single machine or a cluster.
High level collections are used to generate task graphs which can be executed by schedulers on a single machine or a cluster.
Some reasons why you should consider using Dask for your large data:
Scalable Parallel Computing: Dask enables the parallelization of computations across multiple cores and distributed clusters, allowing users to efficiently handle data processing tasks that exceed the memory capacity of a single machine.
Lazy Evaluation: Dask adopts a lazy evaluation approach, deferring the execution of operations until explicitly requested. This optimizes the scheduling and execution of computations, enhancing overall efficiency.
Flexibility Across Data Structures: Dask provides “Big Data” collections that extend common Python data structures (e.g., arrays, dataframes, bags) to handle larger-than-memory or distributed datasets. This flexibility allows users to seamlessly transition between single-machine and distributed computing environments.
Integration with Distributed Computing: Dask seamlessly integrates with a task scheduler, facilitating the scaling of computations from a single machine to distributed computing clusters. This adaptability makes Dask a versatile tool for handling diverse big data processing scenarios.
In essence, Dask offers a versatile and user-friendly framework for scalable, parallel, and distributed computing in Python, making it well-suited for a wide range of data analysis and processing tasks.
Dask Arrays#
Today, we’ll be focusing on processing image data, i.e. array data, with dask, but it can also be used with most any familiar python data variables, like dataframes (pandas-like) for example.
A dask array is very similar to a numpy or xarray array. However, a dask array is only symbolic, and doesn’t initially hold any data. It is structured to represent the shape, chunks, and computations needed to generate the data. Dask remains efficient by delaying computations until the full computation thread is built up and the data is requested. This mode of operation is called “lazy evaluation” and this mode allows users to build up a symbolic thread of calculations before turning them over the scheduler for execution.
dask arrays arrange many python arrays into a grid. The underlying arrays are stored either locally, or on a remote machine like the cloud.

Let’s compare some numpy arrays to dask arrays to illustrate further how Dask operates. We’ll begin by creating a numpy array of ones.
import numpy as np
shape = (1000, 4000)
ones_np = np.ones(shape)
ones_np
array([[1., 1., 1., ..., 1., 1., 1.],
[1., 1., 1., ..., 1., 1., 1.],
[1., 1., 1., ..., 1., 1., 1.],
...,
[1., 1., 1., ..., 1., 1., 1.],
[1., 1., 1., ..., 1., 1., 1.],
[1., 1., 1., ..., 1., 1., 1.]])
Let’s look at the size of this array in memory:
print(f'Size in MB: {ones_np.nbytes / (1024 * 1024)}')
Size in MB: 30.517578125
Now, we’ll create the same array in dask.
import dask.array as da
ones = da.ones(shape)
ones
|
||||||||||||||||
Notice how this array comes with a dask visualization of our array and includes the word “chunks.” Chunks are the way that dask splits the array into sub-arrays. We did not specify how we wanted to chunk the array, so dask just used one chunk for the whole array. At this point, the dask array is very similar to the numpy array and isn’t structured to take advantage of dask functionality.
Specifying Chunks#
To leverage the full power of dask, we’ll split our array into specified chunks. The Dask documentation provides several ways to specify chunks. In this demonstration, we’ll use a block shape.
chunk_shape = (1000, 1000)
ones = da.ones(shape, chunks=chunk_shape)
ones
|
||||||||||||||||
At this point, all we have is a symbolic represetnation of the array, including its shape, data type, and chunk size. This is an example of lazy evalution; unlike numpy, dask has not generated data yet.
In order to generate data, we need to send the data collection to the scheduler, which we can do by calling the compute function.
ones.compute()
array([[1., 1., 1., ..., 1., 1., 1.],
[1., 1., 1., ..., 1., 1., 1.],
[1., 1., 1., ..., 1., 1., 1.],
...,
[1., 1., 1., ..., 1., 1., 1.],
[1., 1., 1., ..., 1., 1., 1.],
[1., 1., 1., ..., 1., 1., 1.]])
Dask has a nifty visualize function that illustrates the symbolic operations that ran when we called compute.
ones.visualize()
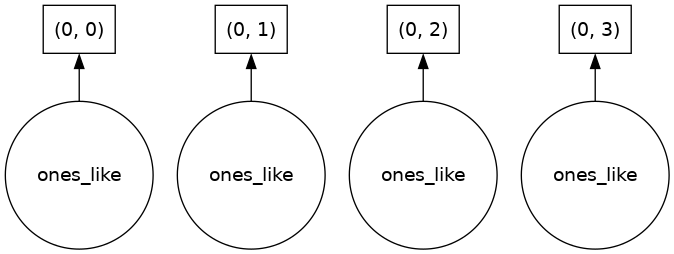
We can see that we stored four “ones-like” arrays, one in each chunk. To generate the data, the dask scheduler calls np.ones four times and then concatenates all of them together into one array.
Rather than immediately loading a dask array (which will store all of the data in RAM), we usually would like to do some kind of analysis on the data and don’t necessarily want to store the full raw data in memory. Let’s see how dask handles a more complex computation that reduces the data.
complex_calculation = (ones * ones[::-1, ::-1]).mean()
complex_calculation.visualize()
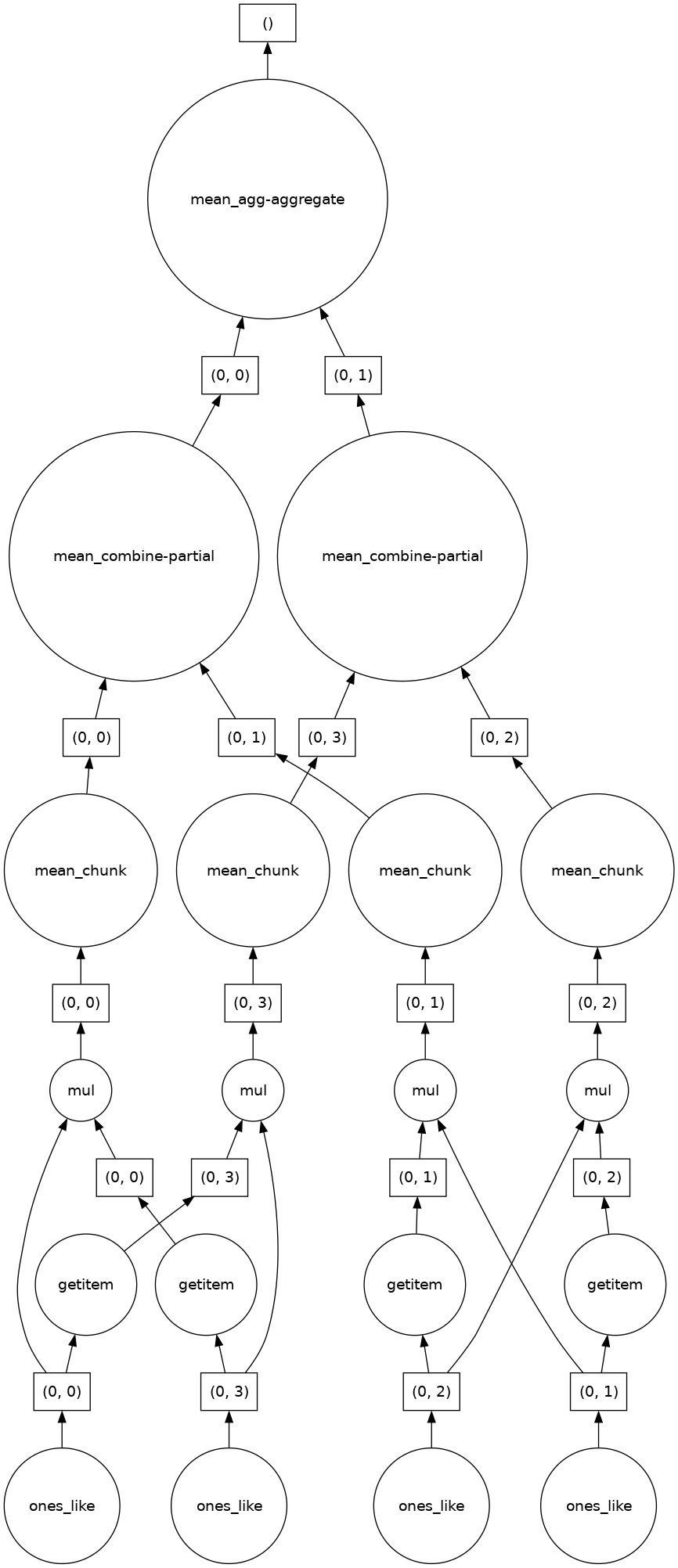
We can see Dask’s strategy for running the calculation thread on our data array. The power of Dask is that it automatically designs an algorithm appropriate for complex operation threads with big data.
Monitor Dask Usage via Dask Dashboard#
Dask offers visualization tools for you to monitor how dask is using memory across your cluster of CPUs and GPUs. This is important when working with large data, because as we’ll see later in this tutorial certain computations can actually add memory usage, potentially exceeding your memory amount while a task is being run or doubling up on computation time making them better to complete outside of dask.
Let’s take a quick look at the dask dashboard which is available to us in CryoCloud.
from dask.distributed import Client
client = Client() # start distributed scheduler locally.
client
Client
Client-7e109575-977d-11ee-8e9b-c67ecc8c5715
| Connection method: Cluster object | Cluster type: distributed.LocalCluster |
| Dashboard: /user/elliesch/proxy/8787/status |
Cluster Info
LocalCluster
bc087156
| Dashboard: /user/elliesch/proxy/8787/status | Workers: 4 |
| Total threads: 4 | Total memory: 30.89 GiB |
| Status: running | Using processes: True |
Scheduler Info
Scheduler
Scheduler-bce8e681-1462-44db-be08-df8d87cd53fa
| Comm: tcp://127.0.0.1:35845 | Workers: 4 |
| Dashboard: /user/elliesch/proxy/8787/status | Total threads: 4 |
| Started: Just now | Total memory: 30.89 GiB |
Workers
Worker: 0
| Comm: tcp://127.0.0.1:38083 | Total threads: 1 |
| Dashboard: /user/elliesch/proxy/36673/status | Memory: 7.72 GiB |
| Nanny: tcp://127.0.0.1:38681 | |
| Local directory: /tmp/dask-worker-space/worker-ir5w817o | |
Worker: 1
| Comm: tcp://127.0.0.1:37927 | Total threads: 1 |
| Dashboard: /user/elliesch/proxy/43069/status | Memory: 7.72 GiB |
| Nanny: tcp://127.0.0.1:39161 | |
| Local directory: /tmp/dask-worker-space/worker-p6wtii8k | |
Worker: 2
| Comm: tcp://127.0.0.1:44083 | Total threads: 1 |
| Dashboard: /user/elliesch/proxy/39349/status | Memory: 7.72 GiB |
| Nanny: tcp://127.0.0.1:39991 | |
| Local directory: /tmp/dask-worker-space/worker-4pjejvkm | |
Worker: 3
| Comm: tcp://127.0.0.1:44569 | Total threads: 1 |
| Dashboard: /user/elliesch/proxy/44609/status | Memory: 7.72 GiB |
| Nanny: tcp://127.0.0.1:40603 | |
| Local directory: /tmp/dask-worker-space/worker-0t2alpee | |
On the left of our screen we’re going to open the dask dashboard. We’ll copy the path listed above in the client into the dashboard to connect our CryoCloud instance to a dashboard. Once the dashboard is up and running, please click on “Task Stream,” “Progress,” “Workers Memory,” and “Graph.”
For the sake of time today, we’ll just look at a couple of the assessment tools available to us in the dask dashboard, but the dask documentation with a more extensive list on what diagnostics are available to you through the dashboard.
Dask For Geoscientific Images#
For this section of the tutorial, we’re going to move into using dask with data types that are of interest to us in the Cryosphere. We’ll work with Landsat data and use dask’s native functionality to stream this data in directly from the cloud while only bringing in the pixels that we are interested in. Once we’ve selected our data of interest, we’ll use machine learning tools that interact with dask to do a basic image segmentation task.
Learning Goals:#
Interacting with a Large Image using Dask
Query a Landsat time-series using stackstac with Planetary Computer
Refine the image query before downloading data
Import the refined image
Running Custom Functions on
Dask+xarrayUsing a custom function for analysis before importing data
Implementing scikit image on dask arrays
Computing Environment#
We will set up our computing environment with package imports. Today we’ll be working with planetary computer, dask, xarray, and scikit image.
Tip: If you need to import a library that is not pre-installed, use pip install <package-name> in a Jupyter notebook cell alone to install it for this instance of CryoCloud. On CryoCloud, your package installation will not persist between logins.
pip install planetary-computer
Collecting planetary-computer
Using cached planetary_computer-1.0.0-py3-none-any.whl (14 kB)
Requirement already satisfied: click>=7.1 in /srv/conda/envs/notebook/lib/python3.10/site-packages (from planetary-computer) (8.1.7)
Requirement already satisfied: pydantic>=1.7.3 in /srv/conda/envs/notebook/lib/python3.10/site-packages (from planetary-computer) (2.5.2)
Requirement already satisfied: requests>=2.25.1 in /srv/conda/envs/notebook/lib/python3.10/site-packages (from planetary-computer) (2.31.0)
Requirement already satisfied: pystac>=1.0.0 in /srv/conda/envs/notebook/lib/python3.10/site-packages (from planetary-computer) (1.9.0)
Requirement already satisfied: pytz>=2020.5 in /srv/conda/envs/notebook/lib/python3.10/site-packages (from planetary-computer) (2023.3.post1)
Requirement already satisfied: packaging in /srv/conda/envs/notebook/lib/python3.10/site-packages (from planetary-computer) (23.2)
Requirement already satisfied: pystac-client>=0.2.0 in /srv/conda/envs/notebook/lib/python3.10/site-packages (from planetary-computer) (0.5.1)
Collecting python-dotenv
Using cached python_dotenv-1.0.0-py3-none-any.whl (19 kB)
Requirement already satisfied: pydantic-core==2.14.5 in /srv/conda/envs/notebook/lib/python3.10/site-packages (from pydantic>=1.7.3->planetary-computer) (2.14.5)
Requirement already satisfied: typing-extensions>=4.6.1 in /srv/conda/envs/notebook/lib/python3.10/site-packages (from pydantic>=1.7.3->planetary-computer) (4.8.0)
Requirement already satisfied: annotated-types>=0.4.0 in /srv/conda/envs/notebook/lib/python3.10/site-packages (from pydantic>=1.7.3->planetary-computer) (0.6.0)
Requirement already satisfied: python-dateutil>=2.7.0 in /srv/conda/envs/notebook/lib/python3.10/site-packages (from pystac>=1.0.0->planetary-computer) (2.8.2)
Requirement already satisfied: urllib3<3,>=1.21.1 in /srv/conda/envs/notebook/lib/python3.10/site-packages (from requests>=2.25.1->planetary-computer) (1.26.18)
Requirement already satisfied: idna<4,>=2.5 in /srv/conda/envs/notebook/lib/python3.10/site-packages (from requests>=2.25.1->planetary-computer) (3.4)
Requirement already satisfied: charset-normalizer<4,>=2 in /srv/conda/envs/notebook/lib/python3.10/site-packages (from requests>=2.25.1->planetary-computer) (3.3.0)
Requirement already satisfied: certifi>=2017.4.17 in /srv/conda/envs/notebook/lib/python3.10/site-packages (from requests>=2.25.1->planetary-computer) (2023.11.17)
Requirement already satisfied: six>=1.5 in /srv/conda/envs/notebook/lib/python3.10/site-packages (from python-dateutil>=2.7.0->pystac>=1.0.0->planetary-computer) (1.16.0)
Installing collected packages: python-dotenv, planetary-computer
Successfully installed planetary-computer-1.0.0 python-dotenv-1.0.0
Note: you may need to restart the kernel to use updated packages.
pip install stackstac
Collecting stackstac
Using cached stackstac-0.5.0-py3-none-any.whl (63 kB)
Requirement already satisfied: pyproj<4.0.0,>=3.0.0 in /srv/conda/envs/notebook/lib/python3.10/site-packages (from stackstac) (3.6.1)
Requirement already satisfied: dask[array]>=2022.1.1 in /srv/conda/envs/notebook/lib/python3.10/site-packages (from stackstac) (2022.11.0)
Requirement already satisfied: xarray>=0.18 in /srv/conda/envs/notebook/lib/python3.10/site-packages (from stackstac) (2023.12.0)
Requirement already satisfied: rasterio<2.0.0,>=1.3.0 in /srv/conda/envs/notebook/lib/python3.10/site-packages (from stackstac) (1.3.8)
Requirement already satisfied: packaging>=20.0 in /srv/conda/envs/notebook/lib/python3.10/site-packages (from dask[array]>=2022.1.1->stackstac) (23.2)
Requirement already satisfied: partd>=0.3.10 in /srv/conda/envs/notebook/lib/python3.10/site-packages (from dask[array]>=2022.1.1->stackstac) (1.4.1)
Requirement already satisfied: cloudpickle>=1.1.1 in /srv/conda/envs/notebook/lib/python3.10/site-packages (from dask[array]>=2022.1.1->stackstac) (3.0.0)
Requirement already satisfied: pyyaml>=5.3.1 in /srv/conda/envs/notebook/lib/python3.10/site-packages (from dask[array]>=2022.1.1->stackstac) (5.4.1)
Requirement already satisfied: toolz>=0.8.2 in /srv/conda/envs/notebook/lib/python3.10/site-packages (from dask[array]>=2022.1.1->stackstac) (0.12.0)
Requirement already satisfied: click>=7.0 in /srv/conda/envs/notebook/lib/python3.10/site-packages (from dask[array]>=2022.1.1->stackstac) (8.1.7)
Requirement already satisfied: fsspec>=0.6.0 in /srv/conda/envs/notebook/lib/python3.10/site-packages (from dask[array]>=2022.1.1->stackstac) (2023.6.0)
Requirement already satisfied: numpy>=1.18 in /srv/conda/envs/notebook/lib/python3.10/site-packages (from dask[array]>=2022.1.1->stackstac) (1.23.5)
Requirement already satisfied: certifi in /srv/conda/envs/notebook/lib/python3.10/site-packages (from pyproj<4.0.0,>=3.0.0->stackstac) (2023.11.17)
Requirement already satisfied: click-plugins in /srv/conda/envs/notebook/lib/python3.10/site-packages (from rasterio<2.0.0,>=1.3.0->stackstac) (1.1.1)
Requirement already satisfied: snuggs>=1.4.1 in /srv/conda/envs/notebook/lib/python3.10/site-packages (from rasterio<2.0.0,>=1.3.0->stackstac) (1.4.7)
Requirement already satisfied: setuptools in /srv/conda/envs/notebook/lib/python3.10/site-packages (from rasterio<2.0.0,>=1.3.0->stackstac) (68.2.2)
Requirement already satisfied: attrs in /srv/conda/envs/notebook/lib/python3.10/site-packages (from rasterio<2.0.0,>=1.3.0->stackstac) (23.1.0)
Requirement already satisfied: affine in /srv/conda/envs/notebook/lib/python3.10/site-packages (from rasterio<2.0.0,>=1.3.0->stackstac) (2.4.0)
Requirement already satisfied: cligj>=0.5 in /srv/conda/envs/notebook/lib/python3.10/site-packages (from rasterio<2.0.0,>=1.3.0->stackstac) (0.7.2)
Requirement already satisfied: pandas>=1.4 in /srv/conda/envs/notebook/lib/python3.10/site-packages (from xarray>=0.18->stackstac) (1.5.1)
Requirement already satisfied: python-dateutil>=2.8.1 in /srv/conda/envs/notebook/lib/python3.10/site-packages (from pandas>=1.4->xarray>=0.18->stackstac) (2.8.2)
Requirement already satisfied: pytz>=2020.1 in /srv/conda/envs/notebook/lib/python3.10/site-packages (from pandas>=1.4->xarray>=0.18->stackstac) (2023.3.post1)
Requirement already satisfied: locket in /srv/conda/envs/notebook/lib/python3.10/site-packages (from partd>=0.3.10->dask[array]>=2022.1.1->stackstac) (1.0.0)
Requirement already satisfied: pyparsing>=2.1.6 in /srv/conda/envs/notebook/lib/python3.10/site-packages (from snuggs>=1.4.1->rasterio<2.0.0,>=1.3.0->stackstac) (3.1.1)
Requirement already satisfied: six>=1.5 in /srv/conda/envs/notebook/lib/python3.10/site-packages (from python-dateutil>=2.8.1->pandas>=1.4->xarray>=0.18->stackstac) (1.16.0)
Installing collected packages: stackstac
Successfully installed stackstac-0.5.0
Note: you may need to restart the kernel to use updated packages.
import numpy as np
import pandas as pd
import xarray as xr
import matplotlib.pyplot as plt
import os
import pystac_client
from pystac.extensions.projection import ProjectionExtension as proj
import planetary_computer
import rasterio
import rasterio.features
import stackstac
import pyproj
import dask.diagnostics
Interacting with a Large Image Using Dask#
Data Import using Planetary Computer and Stackstac#
The Planetary Computer package allows users to stream data stored in Microsoft’s Planetary Computer Catalog directly from the cloud. When combined with stackstac tools, this allows users to query an area of interest and planetary computer will stream all the requested data from that area using dask.
In this tutorial, we are using Planetary Computer to interact with images from Landsat. In particular, we’ll query images that are around the San Francisco Bay, where this tutorial is taking place. To initialize planetary computer, we’ll define a catalog variable and define the coordinate bounds of our image query using rasterio.
catalog = pystac_client.Client.open(
"https://planetarycomputer.microsoft.com/api/stac/v1",
modifier=planetary_computer.sign_inplace,
)
area_of_interest = {
"type": "Polygon",
"coordinates": [
[
[-124.031297, 36.473972],
[-120.831297, 36.473972],
[-120.831297, 39.073972],
[-124.031297, 39.073972],
[-124.031297, 36.473972],
]
],
}
bounds_latlon = rasterio.features.bounds(area_of_interest)
Now we’ll define a time range to search over and the Landsat bands that we are interested in. In our query we limit the data to images that have cloud cover (eo:cloud_cover) less than (lt) 20%.
time_range = '2020-01-31/2021-01-31'
bbox = bounds_latlon
band_names = ['red','green','blue', 'nir08', 'swir16']
search = catalog.search(collections=["landsat-c2-l2"], bbox=bbox,
datetime=time_range,
query={'eo:cloud_cover': {'lt': 20}
})
items = search.get_all_items()
print(f'There are {len(items)} images that fit your search criteria in the database.')
There are 183 images that fit your search criteria in the database.
print(type(items))
<class 'pystac.item_collection.ItemCollection'>
Notice how items has created a pystac item collection of all the relevant image slices from Landsat that are located within our coordinate bounds. Now we’ll use stackstac to turn these into a Dask xarray that we can interact with.
item = items[0]
epsg = proj.ext(item).epsg
stack = stackstac.stack(items, epsg=epsg, assets=['red','green','blue', 'nir08', 'swir16'],
bounds_latlon=bounds_latlon, resolution=30)
stack
<xarray.DataArray 'stackstac-6f74f18ec9af45035c661e3ac7f51d1b' (time: 183,
band: 5,
y: 9674, x: 9558)>
dask.array<fetch_raster_window, shape=(183, 5, 9674, 9558), dtype=float64, chunksize=(1, 1, 1024, 1024), chunktype=numpy.ndarray>
Coordinates: (12/27)
* time (time) datetime64[ns] 2020-02-06T18:51:55.12...
id (time) <U31 'LC08_L2SP_045033_20200206_02_T1...
* band (band) <U6 'red' 'green' ... 'nir08' 'swir16'
* x (x) float64 4.076e+05 4.076e+05 ... 6.943e+05
* y (y) float64 4.327e+06 4.327e+06 ... 4.037e+06
landsat:wrs_type <U1 '2'
... ...
view:off_nadir int64 0
landsat:cloud_cover_land (time) float64 0.19 0.0 0.94 ... 3.0 0.0 5.41
proj:epsg int64 32610
raster:bands object {'scale': 2.75e-05, 'nodata': 0, 'off...
title (band) <U28 'Red Band' ... 'Short-wave Infra...
epsg int64 32610
Attributes:
spec: RasterSpec(epsg=32610, bounds=(407580, 4037010, 694320, 4327...
crs: epsg:32610
transform: | 30.00, 0.00, 407580.00|\n| 0.00,-30.00, 4327230.00|\n| 0.0...
resolution: 30That was fast for a large image cutout! Let’s figure out why. Take a look at the bottom of your CryoCloud Screen and check your memory. You’ll notice that it should be on the order of MBs at this point, and this is because we haven’t yet pulled any data into our CryoCloud environment. Instead we have the directions to the data locations for all of the Landsat images in Planetary Computer, ready to stream into an initialized xarray.
Under the hood, stackstac is using dask to do this. Currently we have the “lazy” load we discussed above implemented. dask allows you to perform parallel and distributed computing on larger-than-memory datasets, but this can be inefficient. Lazy evaluation delays the execution of operations, here that would be pulling in the data to your CryoCloud instance, until the results are actually needed. This approach enables dask to efficiently handle large computations. What we see in the printout above is a symbolic representation of the xarray dimensions for our data.
Why is this evaluation using any memory at all? Check above and see that the table describing your xarray has a row named “Dask Graph.” There we see that our data would be divided into chunks and graph layers. As part of the lazy load, dask has initialized these chunks as empty variables and that is what is currently using memory.
How big would this dataset be if we held it all in memory?
print('projected dataset size (GB): ', stack.nbytes/1e9)
projected dataset size (GB): 676.83715344
Refining our Image Before Data Import#
We know that we have a time-series of 696 images, but perhaps we’re actually interested in behavior averaged over monthly timescales in this region and we only want an rgb image. We can manipulate our stackstac array just like we would with a regular xarray.
rgb = stack.sel(band=['red', 'green', 'blue'])
monthly = rgb.resample(time="MS").median("time", keep_attrs=True)
/srv/conda/envs/notebook/lib/python3.10/site-packages/dask/array/core.py:1760: PerformanceWarning: Increasing number of chunks by factor of 17
return da_func(*args, **kwargs)
Notice how we got a warning that dask is automatically adjusting the chunk size for our xarray object. In dask, the chunk size is a critical parameter that determines how the data is divided into smaller, manageable pieces for distributed processing. When you create or manipulate a dask enabled xarray dataset, dask tries to find an appropriate chunk size based on the size of the data and the available computing resources. This adjustment is made to optimize computational performance once we finally compute our evaluation. For now, we are still in a lazy state, which you can see evidenced by how little memory we are taking up.
We have queried for a rather large image size, and if we were to pull all of that down to our local machine, we might overwhelm the amount of memory available to us on our current CryoCloud instance. Luckily, we can keep using our dask-enabled xarray to further refine our query before pulling the data in. Let’s reproject our data to UTM coordinates so we can pick a specific area of interest based on a length of distance in the x/y plane.
lon, lat = -122.4312, 37.7739
x_utm, y_utm = pyproj.Proj(monthly.crs)(lon, lat)
buffer = 6000 # meters
area_of_interest = monthly.loc[..., y_utm+buffer:y_utm-buffer, x_utm-buffer:x_utm+buffer]
area_of_interest
<xarray.DataArray 'stackstac-6f74f18ec9af45035c661e3ac7f51d1b' (time: 12,
band: 3,
y: 400, x: 400)>
dask.array<getitem, shape=(12, 3, 400, 400), dtype=float64, chunksize=(1, 1, 286, 376), chunktype=numpy.ndarray>
Coordinates: (12/15)
* band (band) <U6 'red' 'green' 'blue'
* x (x) float64 5.441e+05 5.441e+05 ... 5.561e+05
* y (y) float64 4.187e+06 4.187e+06 ... 4.175e+06
landsat:wrs_type <U1 '2'
description <U28 'Landsat Collection 2 Level-2'
landsat:collection_number <U2 '02'
... ...
view:off_nadir int64 0
proj:epsg int64 32610
raster:bands object {'scale': 2.75e-05, 'nodata': 0, 'off...
title (band) <U28 'Red Band' 'Green Band' 'Blue Band'
epsg int64 32610
* time (time) datetime64[ns] 2020-02-01 ... 2021-01-01
Attributes:
spec: RasterSpec(epsg=32610, bounds=(407580, 4037010, 694320, 4327...
crs: epsg:32610
transform: | 30.00, 0.00, 407580.00|\n| 0.00,-30.00, 4327230.00|\n| 0.0...
resolution: 30Import the Refined Image#
Now that we’ve refined our query, without overloading the memory, we can import the refined time-series. This will allow us to do further calculations with it on our CryoCloud instance, or even just allow us to visualize it. Let’s see what we’ve been working with!
Even though we visualized pathways for our toy array above using the built-in visualize function, we don’t recommend running it here, as this will take too long to load.
The compute function in dask triggers the actual data pull. We can monitor the time that it takes using the dask progress bar. While this is processing watch the memory at the bottom of the screen.
with dask.diagnostics.ProgressBar():
data = area_of_interest.compute()
/srv/conda/envs/notebook/lib/python3.10/site-packages/numpy/lib/nanfunctions.py:1217: RuntimeWarning: All-NaN slice encountered
r, k = function_base._ureduce(a, func=_nanmedian, axis=axis, out=out,
/srv/conda/envs/notebook/lib/python3.10/site-packages/numpy/lib/nanfunctions.py:1217: RuntimeWarning: All-NaN slice encountered
r, k = function_base._ureduce(a, func=_nanmedian, axis=axis, out=out,
/srv/conda/envs/notebook/lib/python3.10/site-packages/numpy/lib/nanfunctions.py:1217: RuntimeWarning: All-NaN slice encountered
r, k = function_base._ureduce(a, func=_nanmedian, axis=axis, out=out,
/srv/conda/envs/notebook/lib/python3.10/site-packages/numpy/lib/nanfunctions.py:1217: RuntimeWarning: All-NaN slice encountered
r, k = function_base._ureduce(a, func=_nanmedian, axis=axis, out=out,
Notice how the memory fluctuated, and at times was much higher than the final memory. dask still needed to bring all the data into our cloud instance, but only needed to hold the data from our initial query in memory as long as it was needed to do our calculations. We are now left with a much smaller slice than our initial query, but the slice that we wanted, which a monthly-averaged Landsat time series of a specific area on the map. Now that the data that we wanted all along is in our CryoCloud RAM, let’s visualize it.
First we’ll take a look at data. It’s still an xarray, but we can see that the data is present, and it is no longer held in chunks. Since we know that Landsat doesn’t pass over this location every month, we’ll eliminate the time slices that have no data in them.
data = data.dropna(dim='time', how='all')
data
<xarray.DataArray 'stackstac-6f74f18ec9af45035c661e3ac7f51d1b' (time: 7,
band: 3,
y: 400, x: 400)>
array([[[[0.1191375 , 0.0971925 , 0.1134175 , ..., 0.0223925 ,
0.0194775 , 0.0163975 ],
[0.076595 , 0.0718375 , 0.08809 , ..., 0.0228875 ,
0.020715 , 0.0174975 ],
[0.067025 , 0.0672175 , 0.0660075 , ..., 0.022475 ,
0.02154 , 0.019175 ],
...,
[0.0282775 , 0.034025 , 0.035895 , ..., 0.106845 ,
0.1058 , 0.129725 ],
[0.0482425 , 0.036665 , 0.03529 , ..., 0.1178175 ,
0.10767 , 0.109265 ],
[0.068125 , 0.045575 , 0.0360325 , ..., 0.1108325 ,
0.0946075 , 0.070105 ]],
[[0.10855 , 0.095955 , 0.1162775 , ..., 0.0500575 ,
0.0477475 , 0.0460425 ],
[0.076265 , 0.0768975 , 0.0904 , ..., 0.0495625 ,
0.04871 , 0.0460975 ],
[0.0695 , 0.0739275 , 0.0703525 , ..., 0.0491775 ,
0.0490125 , 0.0480225 ],
...
[0.03978625, 0.05498 , 0.04838 , ..., 0.1190275 ,
0.114765 , 0.1190275 ],
[0.0441725 , 0.047445 , 0.04572625, ..., 0.0853675 ,
0.1276075 , 0.1109975 ],
[0.056135 , 0.044585 , 0.0465375 , ..., 0.08378625,
0.0921875 , 0.07361125]],
[[0.062075 , 0.0539075 , 0.0497825 , ..., 0.04431 ,
0.04431 , 0.0409275 ],
[0.0552275 , 0.04827 , 0.054705 , ..., 0.0489025 ,
0.04431 , 0.0409275 ],
[0.0515425 , 0.049425 , 0.0492875 , ..., 0.0489025 ,
0.0400475 , 0.0409275 ],
...,
[0.02517 , 0.02801625, 0.0305875 , ..., 0.1034625 ,
0.1034625 , 0.1067075 ],
[0.0311925 , 0.026105 , 0.02826375, ..., 0.07764 ,
0.1067075 , 0.09953 ],
[0.039305 , 0.02561 , 0.02517 , ..., 0.07759875,
0.085285 , 0.05994375]]]])
Coordinates: (12/15)
* band (band) <U6 'red' 'green' 'blue'
* x (x) float64 5.441e+05 5.441e+05 ... 5.561e+05
* y (y) float64 4.187e+06 4.187e+06 ... 4.175e+06
landsat:wrs_type <U1 '2'
description <U28 'Landsat Collection 2 Level-2'
landsat:collection_number <U2 '02'
... ...
view:off_nadir int64 0
proj:epsg int64 32610
raster:bands object {'scale': 2.75e-05, 'nodata': 0, 'off...
title (band) <U28 'Red Band' 'Green Band' 'Blue Band'
epsg int64 32610
* time (time) datetime64[ns] 2020-02-01 ... 2020-12-01
Attributes:
spec: RasterSpec(epsg=32610, bounds=(407580, 4037010, 694320, 4327...
crs: epsg:32610
transform: | 30.00, 0.00, 407580.00|\n| 0.00,-30.00, 4327230.00|\n| 0.0...
resolution: 30We’ll use xarray’s native plotting function to visualize the data.
data.plot.imshow(row='time', rgb='band', robust=True, size=6);

Running Complex Python Functions with Dask + Xarray#
In the previous section we showed how dask can be used to pull data from the cloud while refining your search ahead of time to the data and resolutions that you are interested in. In this section we’ll see how dask can be used to do some more complex analyses as well before pulling the data into memory.
dask does have a native package for interacting with images called dask_image, but it can be tricky to use with streaming data in chunks, which makes it difficult to use on large images stored elsewhere in the cloud. We will instead write some custom functions to be used on our dask data, so that we can import our data already transformed.
Implementing Custom Functions with Dask#
Let’s start by looking at the normalized difference vegetation index (NDVI). In the cryosphere, this isn’t likely to be an index that we use often, but it’s a great stand in for how we can create custom functions in dask. This same principal could be applied to pull in our data as band ratios, or other preprocessing functions that we might be interested in. Similarly to above, we’ll limit this to our area of interest.
area_of_interest = stack.loc[..., y_utm+buffer:y_utm-buffer, x_utm-buffer:x_utm+buffer]
area_of_interest
<xarray.DataArray 'stackstac-6f74f18ec9af45035c661e3ac7f51d1b' (time: 183,
band: 5,
y: 400, x: 400)>
dask.array<getitem, shape=(183, 5, 400, 400), dtype=float64, chunksize=(1, 1, 400, 400), chunktype=numpy.ndarray>
Coordinates: (12/27)
* time (time) datetime64[ns] 2020-02-06T18:51:55.12...
id (time) <U31 'LC08_L2SP_045033_20200206_02_T1...
* band (band) <U6 'red' 'green' ... 'nir08' 'swir16'
* x (x) float64 5.441e+05 5.441e+05 ... 5.561e+05
* y (y) float64 4.187e+06 4.187e+06 ... 4.175e+06
landsat:wrs_type <U1 '2'
... ...
view:off_nadir int64 0
landsat:cloud_cover_land (time) float64 0.19 0.0 0.94 ... 3.0 0.0 5.41
proj:epsg int64 32610
raster:bands object {'scale': 2.75e-05, 'nodata': 0, 'off...
title (band) <U28 'Red Band' ... 'Short-wave Infra...
epsg int64 32610
Attributes:
spec: RasterSpec(epsg=32610, bounds=(407580, 4037010, 694320, 4327...
crs: epsg:32610
transform: | 30.00, 0.00, 407580.00|\n| 0.00,-30.00, 4327230.00|\n| 0.0...
resolution: 30NDVI = (area_of_interest.sel(band='swir16') -
area_of_interest.sel(band='nir08')) / (area_of_interest.sel(band='swir16') +
area_of_interest.sel(band='nir08'))
Perhaps we are also interested in obtaining an average NDVI across the entire year. Like before we can write this calculation before computing so that we only keep the data that we’re interested persistant in memory. The persist function is an alternative to calling compute that triggers the computation and stores the results so that subsequent computations can reuse these stored values. This can be useful if we intend to repeat a calculation.
with dask.diagnostics.ProgressBar():
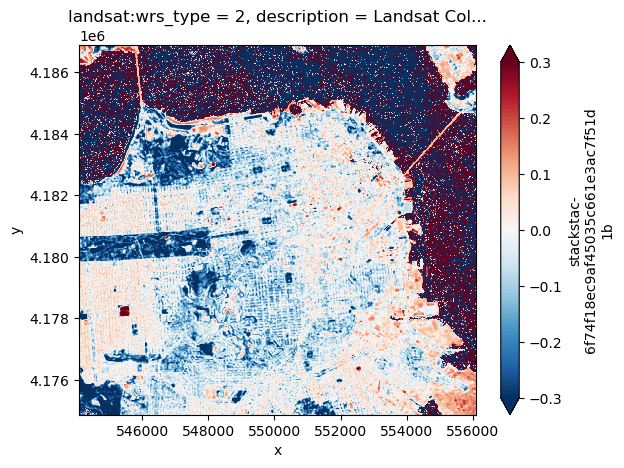
av_NDVI = NDVI.mean(dim='time').persist()
We can visualize this using dask’s built in plotting functionality.
av_NDVI.plot.imshow(vmin=-0.3, vmax=0.3, cmap='RdBu_r')
<matplotlib.image.AxesImage at 0x7f02f0db2080>
Operating Sci-kit Image with Dask for Quick Segmentation#
What if we want to do something more complicated, like something that requires packages from sklearn? We can also pair sklearn functionality with dask arrays. First we’ll take the yearly average of the luminance of our data.
def luminance(dask_arr):
result = ((dask_arr.sel(band='red') * 0.2125) +
(dask_arr.sel(band='green') * 0.7154) +
(dask_arr.sel(band='blue') * 0.0721))
return result
lum = luminance(area_of_interest)
av_lum = lum.median(dim='time')
av_lum
<xarray.DataArray 'stackstac-6f74f18ec9af45035c661e3ac7f51d1b' (y: 400, x: 400)>
dask.array<nanmedian, shape=(400, 400), dtype=float64, chunksize=(302, 302), chunktype=numpy.ndarray>
Coordinates: (12/14)
* x (x) float64 5.441e+05 5.441e+05 ... 5.561e+05
* y (y) float64 4.187e+06 4.187e+06 ... 4.175e+06
landsat:wrs_type <U1 '2'
description <U28 'Landsat Collection 2 Level-2'
landsat:collection_number <U2 '02'
landsat:correction <U4 'L2SP'
... ...
view:off_nadir int64 0
proj:epsg int64 32610
raster:bands object {'scale': 2.75e-05, 'nodata': 0, 'off...
epsg int64 32610
band <U6 'blue'
title <U28 'Blue Band'av_lum.plot.imshow(cmap='Greys_r')
<matplotlib.image.AxesImage at 0x7f02f0598fd0>

We still haven’t computed our data, so this is still operating in lazy load, which means that even though we had to bring the data into memory for our plot we didn’t hold it there, and so dask produced the image and then removed the data from memory.
We are about to switch over to using a function from another package, sci-kit image, and this function will require pulling the data into memory in order to run a more complex function. This means that it is important to have enough memory to allow for the function to store whatever copies of the data it needs while it is computing, but it will only save the output in memory.
from skimage.filters import gaussian
def apply_gaussian(arr):
return gaussian(arr, sigma=(0, 0.1), preserve_range=True, mode='reflect')
smoothed = xr.apply_ufunc(apply_gaussian, av_lum,
dask='allowed', output_dtypes=[np.float64],
input_core_dims=[['x', 'y']], output_core_dims=[['x', 'y']])
np.mean(smoothed)
<xarray.DataArray 'stackstac-6f74f18ec9af45035c661e3ac7f51d1b' ()>
array(0.07944183)
Coordinates:
landsat:wrs_type <U1 '2'
description <U28 'Landsat Collection 2 Level-2'
landsat:collection_number <U2 '02'
landsat:correction <U4 'L2SP'
landsat:collection_category <U2 'T1'
gsd int64 30
view:off_nadir int64 0
proj:epsg int64 32610
raster:bands object {'scale': 2.75e-05, 'nodata': 0, 'off...
epsg int64 32610
band <U6 'blue'
title <U28 'Blue Band'Once we have run a gaussian filter on our data, we can run a simple threshold our images for a basic segmentation. This will not be as nice as segmentation done with more complex computer vision methods, but can be useful for finding easily delineated objects.
absolute_threshold = smoothed > 0.175
absolute_threshold.plot.imshow(cmap='Greys_r')
<matplotlib.image.AxesImage at 0x7f02f066d060>

If we wanted to run machine learning models using sci-kit learn we could apply the same principle. The really beautiful thing about using dask for these tasks is that our initial dataset was estimated to be >600 GB, and we are able to do these relatively high level tasks while streaming in only 20.22 GB that we needed. If we needed to be careful, we could be even more specific about how we implement dask to ensure that we are incredibly efficient with our persistant memory usage.
For a deeper dive into using dask with an applied Cryosphere project, head to Jonny Kingslake’s tutorial on using ARCO data with zarr and dask.